



























- Knowledge-heavy workflows (audit, compliance, document review, regulatory reporting) are where generative AI delivers the most measurable impact in enterprise environments. These processes depend on reading, interpreting, and acting on unstructured information, which is exactly what LLMs do well.
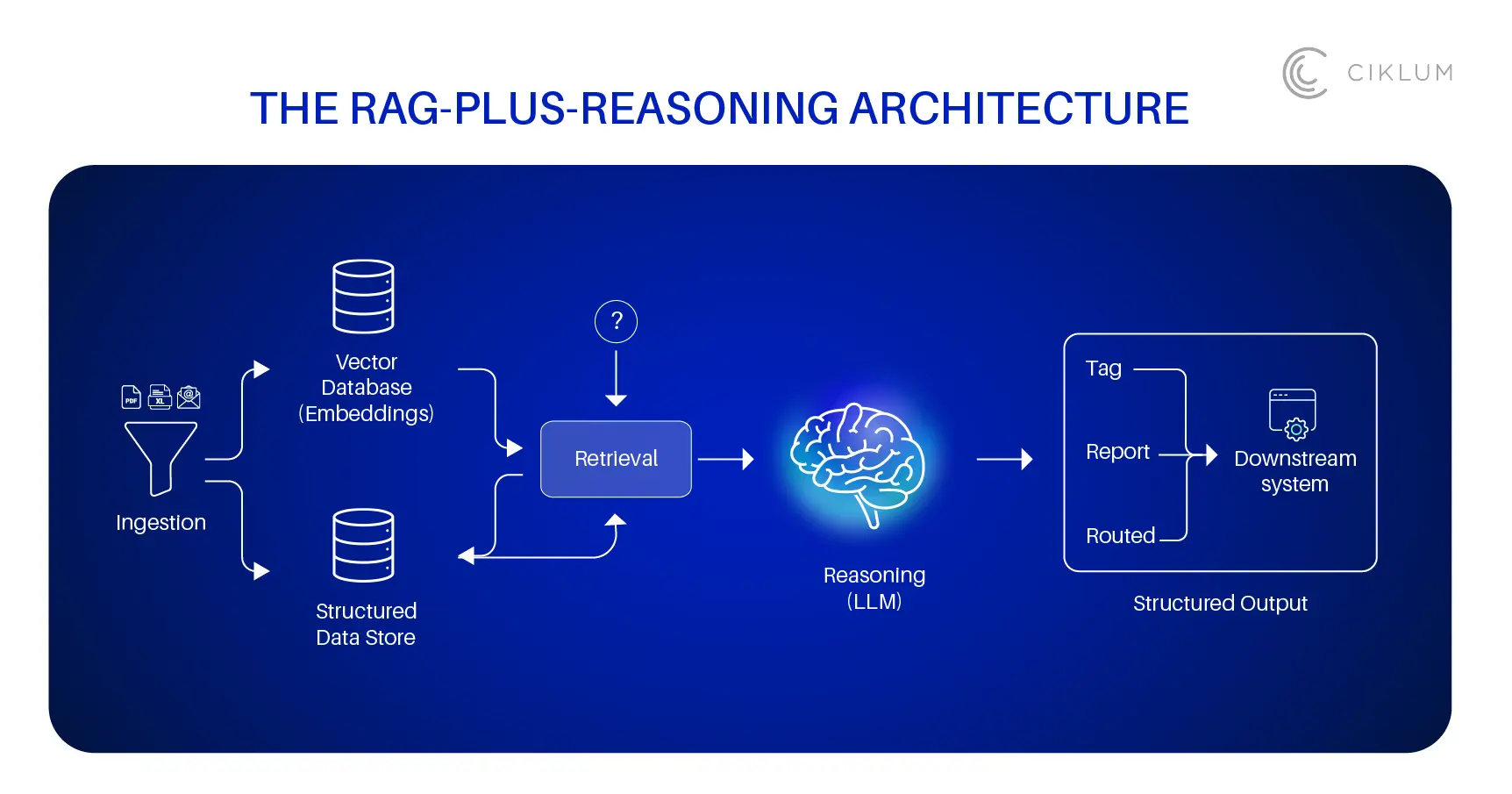
- The pattern that works: ingest documents, retrieve relevant context, reason through the task, and produce a structured output.
- Instead of disappearing, the role of human review transforms: it shifts from performing the work to verifying it. This shift in focus is the source of the time savings.
Every enterprise has workflows that run on reading. An auditor reads thousands of findings and assigns categories. A compliance analyst reads regulatory filings and checks them against internal policy. A mortgage processor reads stacks of documents, validates signatures, and tracks deadlines. A sales rep spends two hours assembling a document that should take ten minutes to produce.
These are knowledge-heavy workflows. They require interpretation, judgment, and familiarity with internal rules. They are also the workflows where the most experienced, most expensive people spend the largest share of their time on the most repetitive parts of their job.
Generative AI is changing how enterprises handle this kind of work. Not by replacing the people who do it, but by handling the reading, extraction, classification, and first-pass reasoning so that humans can focus on the exceptions and the decisions that actually need their judgment.
What Makes a Workflow "Knowledge-Heavy"
The common thread across these processes is unstructured input. The information arrives as PDFs, emails, scanned forms, free-text notes, or spreadsheets with inconsistent formatting. Traditional automation (RPA, rule-based systems) works well when inputs are structured and predictable. It breaks when they are not.
Knowledge-heavy workflows also require context. Categorizing an audit finding is not just pattern matching. It requires understanding what the finding means in the context of the organization's compliance framework, its prior audit history, and the specific regulatory requirements that apply. A mortgage transfer requires knowing the bank's SLA policies, the document requirements for the Portuguese Banking Association, and whether the signatures on page 14 match the records in the core banking system.
This is where generative AI fits. LLMs can read unstructured text, interpret meaning in context, and produce structured outputs. When combined with retrieval systems that pull relevant internal data before the model reasons (the RAG pattern), they can operate within the organization's own knowledge rather than relying on general training data.
The Architecture: Retrieve, Reason, Output
The pattern showing up across production deployments follows a consistent structure:
- Ingestion. Documents, filings, records, and correspondence are parsed and stored. Text is chunked and embedded into a vector database. Structured data goes into a conventional data store.
- Retrieval. When a task arrives (a new filing to classify, an audit finding to categorize, a mortgage transfer to process), the system retrieves the most relevant context: prior decisions, applicable policies, related records.
- Reasoning. An LLM reads the retrieved context alongside the new input and works through the task. It classifies, extracts, compares, summarizes, or drafts, depending on the workflow.
- Structured output. The result is delivered in a typed format (a classification tag, a compliance report, a routed document) that downstream systems can consume without manual re-entry.
This is not theoretical. Ciklum built exactly this architecture for a billion-dollar pharmaceutical company that needed to categorize 400,000+ audit findings. The previous process was manual. Analysts assigned categories by reading each finding individually, and the error rate was high enough to undermine leadership decisions about lab training and drug prescriptions. The ML pipeline replaced manual classification with automated, context-driven tagging using unsupervised learning and coherence modeling. Every tag was traceable back to the source data, so leadership could trust the output.
Where This is Running in Production
The strongest results emerge in high-volume workflows where information is unstructured and the cost of errors is measurable. Mortgage transfer processing is a clear example.
Ciklum partnered with Santander Portugal to automate mortgage transfer processes across the Portuguese Banking Association network. The bank was handling more than 100 transfer requests per day, each requiring manual document processing, correspondence management, and signature validation.
The automated system, built on Appian and powered by intelligent document processing, enabled consistent compliance with the 8-day SLA, reduced document errors, and freed up FTE capacity previously consumed by repetitive manual tasks.
In financial services more broadly, agentic RAG systems are being deployed for fraud detection and regulatory compliance. These systems pull context from regulatory databases, transaction histories, and customer records in real time. They synthesize that information to flag suspicious patterns, verify identities, and generate audit trails. The difference from traditional rule-based fraud detection is that RAG-based systems adapt to new patterns without requiring manual rule updates.
In automotive manufacturing, a UK-based manufacturer partnered with Ciklum to automate regulatory reporting and compliance document processing. The system reduced compliance processing costs by 80% and uncovered over £10M in procurement inefficiencies through process mining. The regulatory documents themselves had been a bottleneck: manual data collation was slow, error-prone, and difficult to audit. The automated pipeline handles collation, accuracy checks, and real-time updates.
In healthcare, a regenerative medicine nonprofit was losing two hours per opportunity because sales representatives were manually assembling export documents. Ciklum standardized document creation across the enterprise using Salesforce Sales Cloud, cutting that latency and giving reps more time for actual selling.
What Changes for the People Doing This Work
The most common concern about automating knowledge-heavy work is that it eliminates the roles of the people who do it. In practice, the opposite has happened in every deployment described above. The work changes, but the people stay.
An auditor who used to spend 70% of their time on initial classification now spends that time reviewing the system's classifications and investigating the findings that matter most. A compliance analyst who used to manually check filings against policy now reviews the system's assessment and focuses on the edge cases. A mortgage processor who spent hours on document validation now handles exception management and client communication.
The role shifts from creator to reviewer. The human becomes the quality check rather than the production line. That is where the time savings come from, and it is also where organizations retain the judgment and institutional knowledge that the AI cannot replicate.
Recent research supports this pattern. A 2025 study on AI agents for enterprise document assessment found that AI-powered systems achieve 99% information consistency (compared to 92% for human reviewers alone) and reduce review time from 30 minutes to 2.5 minutes per document, while maintaining 95% agreement with expert human judgment. Human oversight remains in the loop, particularly for specialized domains and high-stakes decisions.
Getting Started
Every enterprise has a version of this problem: highly skilled people spend a disproportionate amount of time reading, classifying, and summarizing before they can do the work that actually requires their expertise. That imbalance is where generative AI delivers the clearest return.
The organizations making progress are not chasing use cases. They are identifying the specific bottleneck, usually audit, compliance, document processing, or regulatory reporting. Then, they map the interpretation steps and build a RAG pipeline around that one workflow. Human judgment stays in the loop. The AI takes on the volume. And the people who were buried in documents start spending their time on the decisions that matter.

By Ciklum Editorial Team

Ciklum’s Editorial Board is a collective of experienced writers and industry experts, bringing together perspectives shaped by real-world engineering and delivery experience. Through collaborative insights, the team explores how technology, AI, and digital innovation move from concept to execution across industries.
Blogs
Discover Similar Insights

Beyond Cost Savings: The Real Value of AI Automation for Enterprises
Learn More
Rewrite Your PDLC: Why AI‑Driven Prototyping is the New Standard in FinTech
Learn More
Why AI Automation Fails Without Modern Enterprise Data Platforms
Learn More
AI Agents in the Enterprise: Hype, Reality, and Where They Actually Deliver Value
Learn More