



























- Key Takeaways
- The Problem Nobody Wants to Admit
- Enterprise AI Knowledge Management: What a Knowledge Engine Actually Does
- Knowledge Base vs Knowledge Engine: The Difference Matters
- Why SharePoint, Confluence, and Notion Are Not Enough
- Agentic RAG and the Knowledge Layer
- PRODIGY: Built for the Environments Most Platforms Avoid
- The Real Bottleneck Isn't Code. It's Everything Before It.
- From AI Pilot to Production: What the Timeline Actually Looks Like
- Why Legacy Systems and Regulation Break Enterprise AI
- The Question Every Executive Should Ask Before Their Next AI Investment
Key Takeaways
- A governed knowledge layer is what separates AI as a feature from AI as infrastructure.
- A Knowledge Engine connects, structures, governs, and activates enterprise context.
- Scaling enterprise AI requires orchestration and context, not better prompts.
- Compliance failures kill more pilots than bad algorithms.
- Without robust enterprise AI knowledge management, even well-funded programmes stall at the same point.
- The foundation determines the lifespan of your AI strategy.
The Problem Nobody Wants to Admit
Long gone are the days when leadership teams debated “should we use GenAI?” The question now is harder, and almost always comes back to enterprise AI knowledge management: “Why do so many pilots stall the moment it is time to scale?
Here is a scenario that will feel familiar to many enterprises. Your organisation has run ten AI pilots in the last 18 months. Three are in production. Two of those are barely used. The others stalled somewhere between proof-of-concept and the compliance team.
Enterprise AI fails to scale for reasons that have almost nothing to do with the model. The actual blockers are:
- Fragmented knowledge: Data still lives in email threads, stale SharePoint folders, outdated Confluence pages, and half-accurate Jira backlogs.
- Ungoverned access: Access rules were built for people, not AI. So when agents start pulling from enterprise systems, sensitive information can appear in places it was never meant to reach.
- No audit trail: When a regulator or internal risk function asks how a recommendation was generated, there is no documented answer.
- Context collapse: Agents that performed brilliantly in a controlled demo encounter the full complexity of the real environment and stop performing.
What is missing is a coherent, governed AI knowledge layer that turns scattered knowledge into something AI can actually use, audit, and trust. That is what a knowledge engine is. Without one, you just have a collection of expensive experiments.
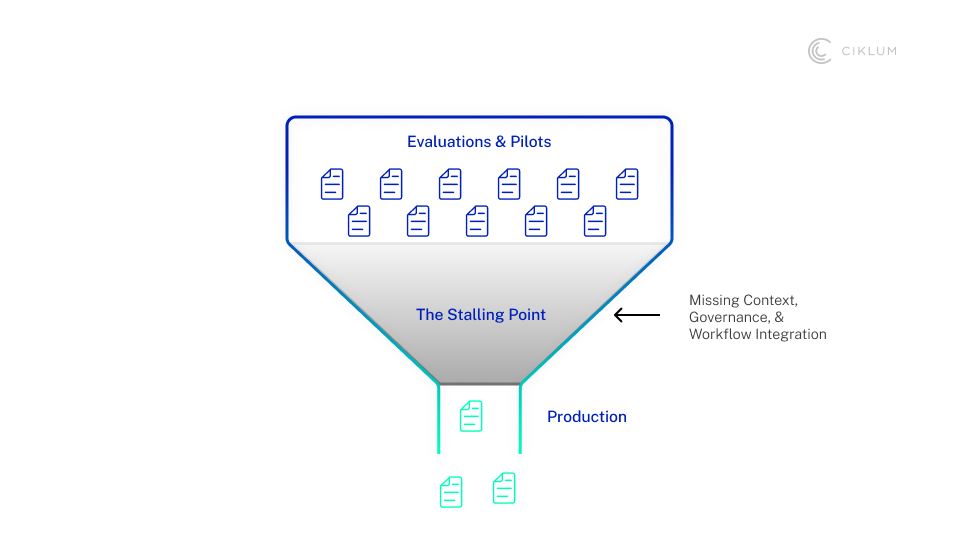
Enterprise AI Knowledge Management: What a Knowledge Engine Actually Does
The term has been used a lot lately. So let's be precise. A knowledge engine is the bridge between your enterprise's raw information and the agents or copilots that need to act on it. Not a database. Not a search tool. It is an active, governed system that operates continuously across the organisation.
Asana's research suggests that as much as 60% of work time is spent searching for information, switching between apps, and chasing status updates. That inefficiency is the exact friction layer AI inherits when you try to scale it. A knowledge engine is designed to collapse it.
It does four things simultaneously.
It connects
Email, file stores, code repositories, ticketing systems, collaboration tools, wherever knowledge lives, the engine reaches it. That includes the systems nobody wants to touch: the COBOL services your core banking platform depends on, the legacy claims engine that never exposed a clean API. AI cannot operate responsibly if it understands the modern layer and ignores the infrastructure underneath.
It normalizes and enriches
Raw content is not useful to an agent. The engine structures it, tags it, and links it to the business entities that matter — customer, product, case, transaction, risk event. An email thread about a disputed claim becomes part of that claim's context. A Jira ticket becomes traceable to the service it describes.
It governs
Nearly three in four organizations plan to deploy agentic AI within two years, yet only a small minority report mature governance frameworks for autonomous agents. A knowledge engine closes that gap. Access rights are inherited and enforced, and sensitive content is redacted at query time.
It makes knowledge usable
Not just retrievable. The difference matters. A retrieval system finds documents. A knowledge engine understands context, resolves ambiguity, and serves the right information to the right agent at the right moment in a workflow.
Knowledge Base vs Knowledge Engine: The Difference Matters
A knowledge base stores content. A knowledge engine activates it.
That distinction matters because many enterprise AI initiatives treat knowledge management as a storage problem. They assume the answer is to clean up the wiki, migrate documents, or connect a chatbot to an existing repository.
Those things may help, but they are not enough.
A knowledge base can show an employee where a policy document lives. A knowledge engine goes further by identifying which version of that policy applies to a specific customer, case, market, product, or risk scenario. It can enforce access controls, trace the source, guide the output through the correct approval path, and serve that context to an AI agent inside a workflow.
For enterprise AI, this is the whole point. AI does not just need more content. It needs the right context, with the right controls, at the right moment.
Why SharePoint, Confluence, and Notion Are Not Enough
Most enterprises already have knowledge tools. SharePoint, Confluence, Notion, internal wikis, document libraries, project boards, and plenty more. But these tools were built for people to search, browse, update, and interpret information.
AI agents need something different. They need structured context, traceable sources, automatically enforced permissions, and a clear way to know which document is current, which process is outdated, and which system record should take priority.
A governed knowledge engine does not replace every enterprise tool. It sits above and across them. It connects what already exists, resolves the messy context between systems, and turns fragmented knowledge into something AI can safely use.
That is the missing layer in most AI operating models.
Agentic RAG and the Knowledge Layer
"Agentic RAG" — retrieval-augmented generation built for autonomous agents — is the architecture pattern UK and EU enterprises are actively evaluating right now. It has become one of the most important ideas in enterprise AI at scale by moving retrieval from a passive search process to an active reasoning process.
Rather than relying on a model's training data, agents retrieve relevant information from a defined knowledge source before generating a response. This makes outputs more accurate, more traceable, and far easier to govern.
The more autonomous the agent becomes, the more important the knowledge layer becomes. An agent that can reason across systems is only as reliable as the information it can access, the permissions it respects, and the audit trail it leaves behind. If the enterprise data is fragmented, inconsistently tagged, or ungoverned, retrieval-augmented agents inherit all of that noise. You would see outputs that are plausible but wrong, or accurate but unauditable.
PRODIGY’s Knowledge Engine works like an RAG enterprise knowledge base for AI agents, but with governance, source traceability, and workflow context built in.
PRODIGY: Built for the Environments Most Platforms Avoid
PRODIGY is Ciklum's AI platform — a combination of methodology and proprietary accelerators, of which the Knowledge Engine is one of the most foundational. The distinction between methodology and platform matters because most enterprise AI problems are not purely technical. They are also organizational. They require a structured way of thinking about how AI is built and governed inside a large enterprise.
The platform is built around three categories of accelerators.
- Technical accelerators — including the Knowledge Engine — are the agents that speed up the delivery of AI solutions and the AI product development lifecycle.
- Horizontal accelerators address cross-functional enterprise problems: supply chain, IT operations, HR, and finance.
- Vertical accelerators go deep and solve specific problems in regulated industries — banking, healthcare, insurance, retail, and more — where regulatory surface area is large, and tolerance for error is low.
The Knowledge Engine sits at the foundation of all three. It is what makes every agent actually intelligent in context, rather than just competent in a demo.
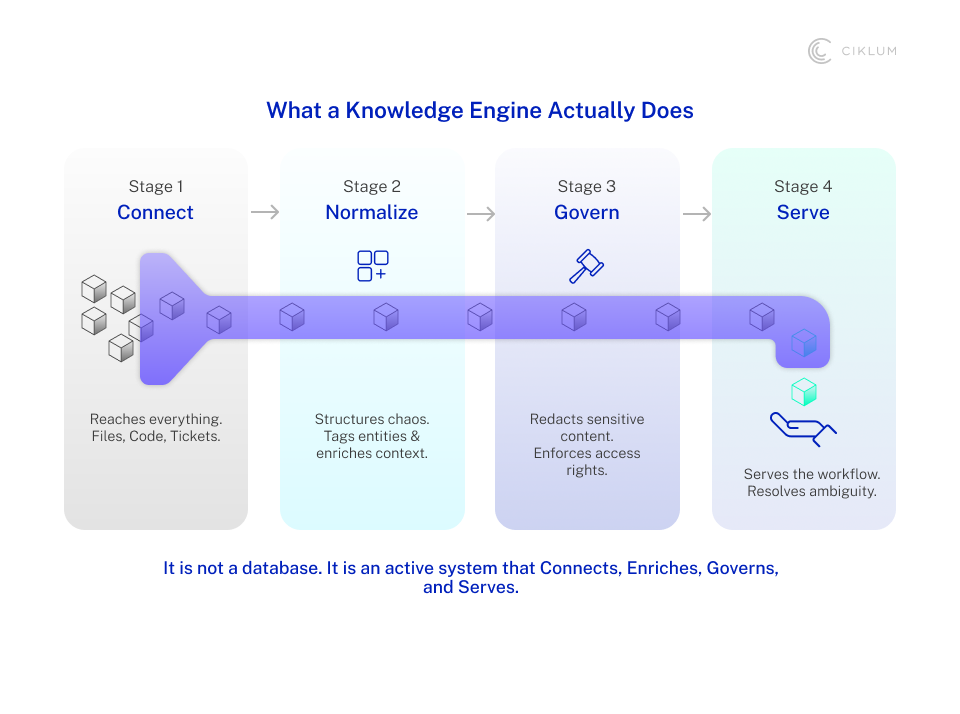
The platform is also deliberately vendor-agnostic. Two years ago, GPT-4 dominated enterprise AI. Today, Claude accounts for more than half of enterprise usage. No ten-year vendor contract was built for a market that moves like this. PRODIGY supports over 2,215 models across more than 114 providers, deployable on any cloud. This is because the platform your team is locked into today may not be the right one in eighteen months. Agents deploy directly into your environment, so your data never leaves your estate, and your security team stays in control.
The Real Bottleneck Isn't Code. It's Everything Before It.
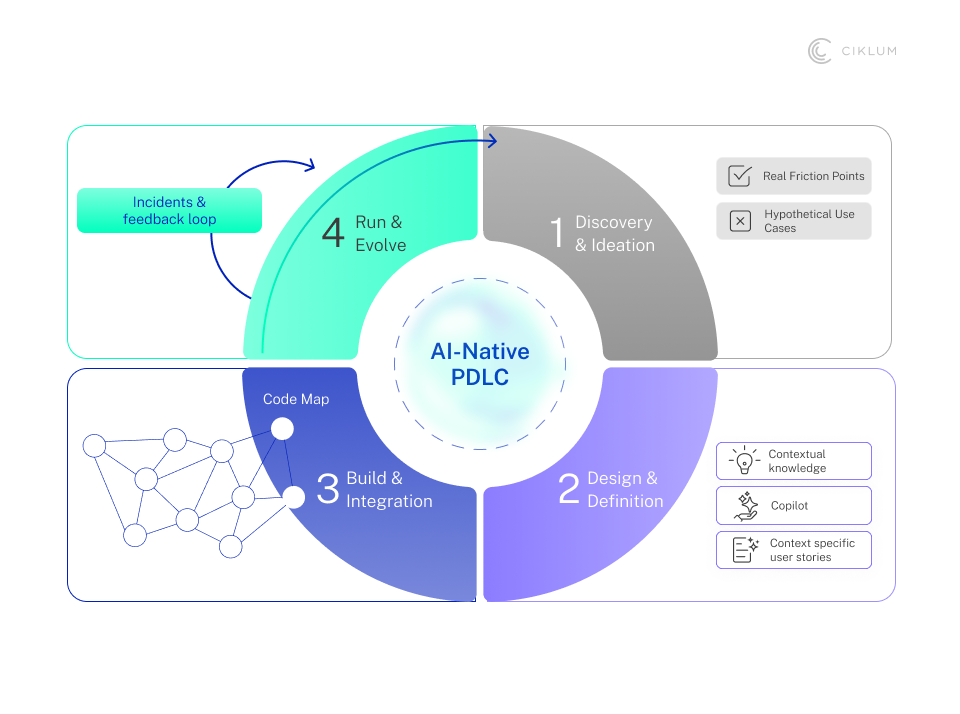
One persistent misconception in enterprise AI is that faster delivery means faster code generation. It does not. Most time lost in AI product development disappears before a single line of code is written: in discovery, requirement definition, and understanding the existing system well enough to know what you are building.
PRODIGY’s Knowledge Engine changes this by making internal knowledge active across the lifecycle.
In the Research and Ideation Phase
Agents mine internal knowledge emails, support tickets, operational logs, and engineering documentation — to surface actual problems and constraints. Not hypothetical use cases. Actual friction points from the systems your people use every day.
In the Design Phase
Teams generate user stories, acceptance criteria, and test cases grounded in actual discovery work. Gaps get flagged before they become defects. Edge cases that would have slipped through to QA get caught at the source.
In the Build Phase
Developers often spend the first few weeks digging through old notes, chasing down the right person, or simply guessing. The Knowledge Engine removes that detective work. Constraints, decisions, and relevant context surface directly in the IDE, so engineers build from a shared understanding of what was agreed, not their best interpretation of it.
In the Run Phase
Monitoring agents track performance, user feedback, and incidents, and surface suggestions for improvement. The product does not get handed over and forgotten, but it keeps learning from what is actually happening.
This is AI-native product development in practice. Not faster sprints within a traditional model, but a fundamentally different way enterprise software is conceived, built, and improved.
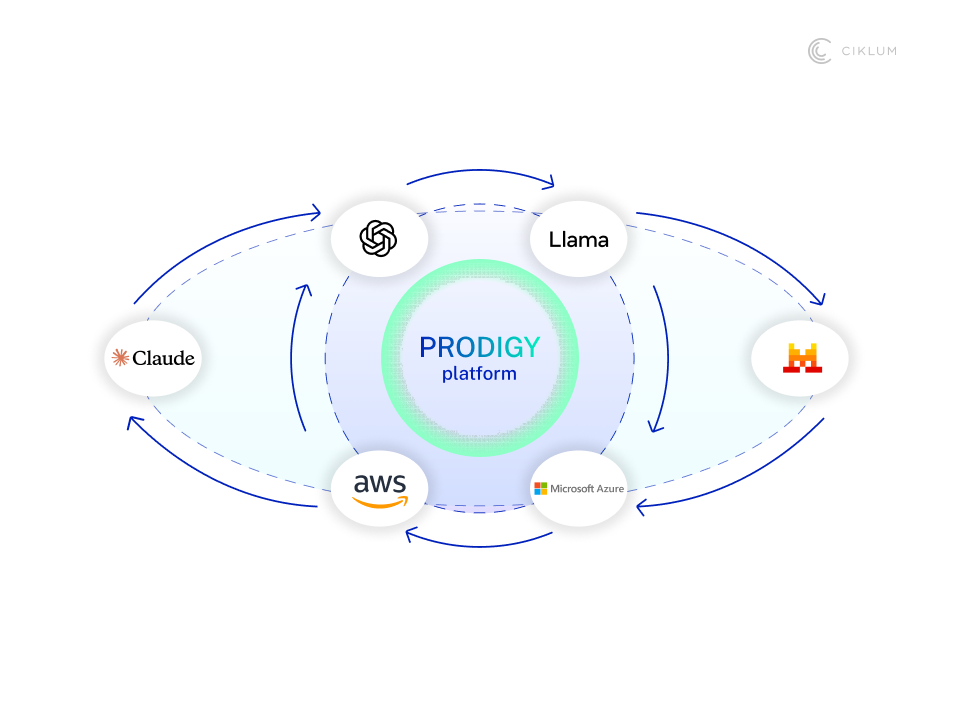
From AI Pilot to Production: What the Timeline Actually Looks Like
The question enterprise teams rarely ask out loud but almost always mean is: how long will this actually take?
The honest answer depends on how ready the knowledge foundation is. If sources are connected, governed, and usable, teams move with less friction. If they are still being cleaned up mid-project, the pilot slows down before it reaches production.
Gartner predicts that through 2026, organisations will abandon 60% of AI projects unsupported by AI-ready data. That makes the timeline question a readiness question.
Moving from AI pilot to production usually depends on four phases: identifying the use case and knowledge sources, connecting and permissioning that knowledge, building agents around the workflow, and putting monitoring, auditability, and feedback loops in place.
With a governed knowledge layer in place, scaling enterprise AI becomes less dependent on hero effort. Teams spend less time reconstructing context and more time building around it.

Why Legacy Systems and Regulation Break Enterprise AI
In UK financial services, an AI agent cannot just produce a useful recommendation. It has to show whether the user had permission to access that information and whether the output followed the right policy path. For teams operating under FCA oversight, that level of control is central to making AI usable in real workflows.
Healthcare faces the same challenge with even more sensitivity. AI may need to work across patient records, clinical guidance, operational policies, and internal documentation. A governed knowledge layer helps reduce compliance risk by enforcing access controls, tracing every output back to its source, and keeping sensitive information inside the right boundaries.
The Question Every Executive Should Ask Before Their Next AI Investment
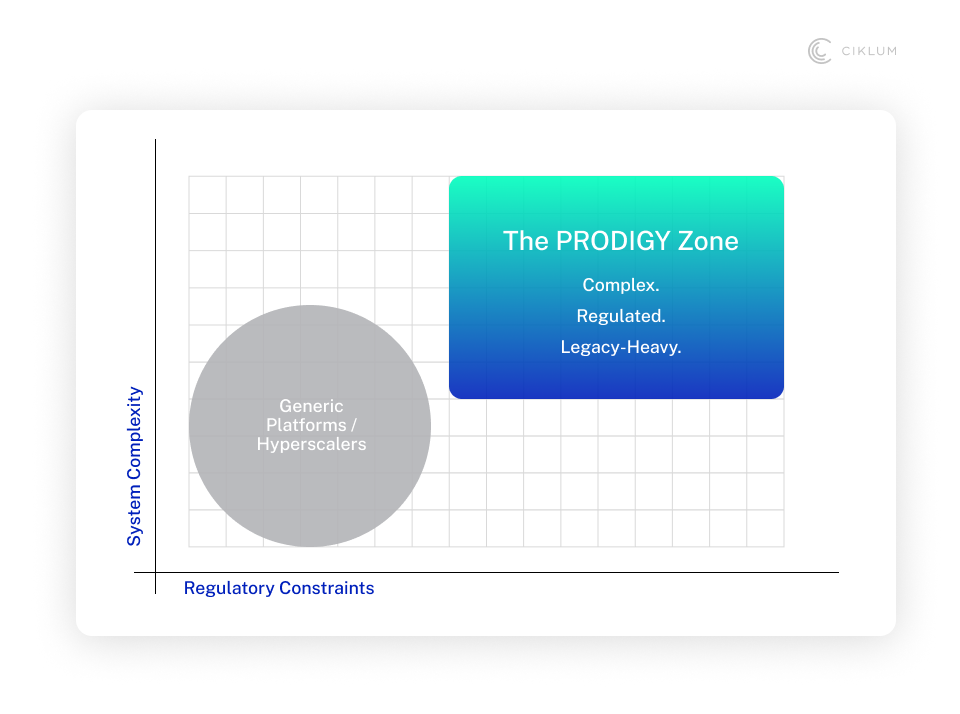
The "AI platform" category is becoming crowded. Every major software vendor has layered one onto their existing stack. Most work well enough until your environment proves too complex, too legacy-heavy, or too regulated for the default setup.
PRODIGY is built for what falls outside that default. For the insurer still running a policy system last updated in 2004, where half the business logic lives in legacy code. For the health system, where a data leak is not a PR issue, it is a regulatory and patient risk.
The question worth asking before your next investment is whether your platform has a knowledge layer strong enough to survive contact with your actual environment. Or whether you will be rebuilding it when the next wave of pilots hits the same wall.
Production-ready AI in a complex enterprise is not just about having agents. It is about having the methodology, governance, and knowledge infrastructure to use them the right way. That is where PRODIGY starts and where most platforms stop.
Ready to put enterprise AI knowledge management at the centre of your AI strategy? Start the conversation here.

By Yannique Hecht

Senior Director - AI R&D
13+ Exp
Yannique Hecht is the Senior Director of AI R&D at Ciklum, and a strategist with 13+ years of experience building at the intersection of product, AI, and strategy. He has led large, cross-functional teams and advised Fortune 500 companies on designing, building, and scaling next-generation digital products and AI-driven platforms.
Blogs
Discover Similar Insights

AI Governance in Practice: Why Enterprise AI Strategies Fail Before They Scale
Learn More
Beyond Cost Savings: The Real Value of AI Automation for Enterprises
Learn More
Enterprise AI Automation vs RPA: Why Rules Alone No Longer Scale
Learn More
Enterprise AI Automation Explained: From Rule-Based Automation to Intelligent Systems
Learn More