



























New innovations in the world of Generative AI are coming on stream all the time - and the next one to really gain traction is Retrieval-Augmented Generation (RAG). This innovative approach to Natural Language Processing combines the results of a semantic search in datasets, and the generation of new text based on the retrieved information.
RAG is the brainchild of Meta, as its research team focused on advancing natural language processing capabilities within large language models. It looks set to cut out many of the AI ‘hallucinations’ that are often suffered by large language models, and ensure that the content it generates is more accurate and more up-to-date. Crucially, at a time when use of public or private data for AI is under the microscope, it can also enable the use of that data without putting it out for use by others.
As a result, RAG-based models represent another level above the tools like ChatGPT that are commonplace at the moment. But before any deployment, it’s vital to understand how they work, where they can be used, and the potential challenges to be aware of along the way.
How does RAG work?
RAG systems work by correlating user prompts with relevant data, identifying the piece of data that is the most semantically similar. This data is used as the context for the prompt, which is then passed to the LLM so that it can provide a relevant, contextual answer. In short, there are four steps to the process: create external data, retrieve relevant information, augment the LLM prompt, update the knowledge base.
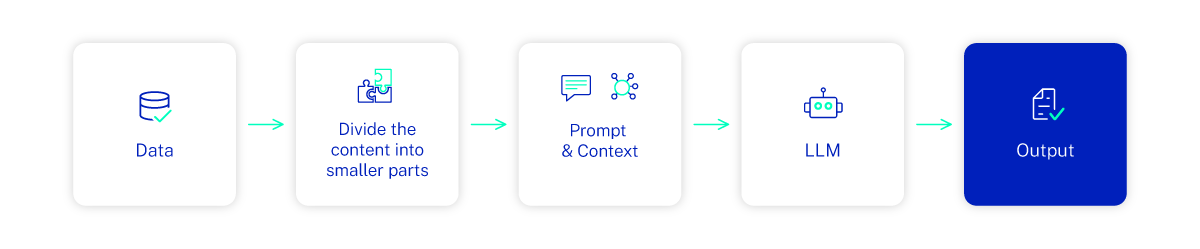
The key difference compared to non-RAG LLMs is that the model can utilize the user’s query and the relevant data at the same time, rather than relying solely on the user input and the data it’s already been trained on.
Where can RAG currently be used?
RAG is already being deployed in several different use cases, and is already proving its worth above the LLMs that preceded it:
 Chatbots:
Chatbots:
A new level of service can be delivered by using RAG for chatbots. Instead of searching through a database to find the most appropriate answer to a user query, RAG models can create more relevant and contextual answers in a huge range of different situations. They’re also capable of understanding queries in one language, and retrieving information and giving answers in another. Content creation:
Content creation:
Being able to retrieve information from diverse sources means that content creation can be streamlined, with the generation of content based on relevant topics or user prompts. This is especially helpful when trying to summarize texts or develop concise reports. Research & personalized learning:
Research & personalized learning:
RAG can support detailed research or the compilation of statistics. Connecting the LLM to news sites, social media feeds or other data points means that up-to-date information can be fed to users directly.The integration of LLMs with more specific data improves the reliability and accuracy of its responses, reducing the risk of generic responses, missing information or inaccurate content.
The benefits - and the challenges - of RAG
As with any new technology, there are all sorts of benefits to enjoy by successfully deploying RAG:
Accurate, up-to-date responses:Instead of being based on static, stale training data, RAG models use up-to-date sources to generate accurate, timely responses.
Fewer hallucinations:
The focus on relevant, external knowledge cuts the risk of the model responding with information that’s either incorrect or simply fabricated. Indeed, outputs can even include citations of original sources, which allows for easy human verification of the content produced.Domain-specific responses:
RAG allows responses to be contextually tailored to the proprietary or domain-specific data of the organization using it.
Efficient, cost-effective deployment:
RAG is a much simpler and cost effective way of utilizing LLMs with domain-specific data, as the model itself doesn’t need to be customized. This is especially beneficial when models frequently need to be updated with new data.
Improved privacy:
RAG owners have control of their data.However, we believe there are three initial challenges emerging, which mean that RAG - just like any other LLM or AI deployment - should be handled with care:
Potential bias:Any retrieval models that are unable to select the most relevant data will have a major negative impact on output. This can be caused by biases in training data, or a tendency for the model to favor some types of data and content over others, which means ensuring neutral responses is a complex but necessary challenge to overcome.
Domain generalization:
The original RAG model was trained on datasets based around Wikipedia, which means it works well with domain-specific data of that style, but can struggle with others.
Handling ambiguity:
Any queries that are unclear in context, lacking intent or are just ambiguous tend to be challenging for RAG models, which depend on the accuracy of the input query. This can lead to the generation of content that is simply irrelevant to the intended purpose.

How will RAG shape the future?
RAG has the potential to transform industries, adding vital personalization, automation and more informed decision-making to everyday operations, driving meaningful business and organizational value. For example, in healthcare, RAG could retrieve relevant health records and quickly generate accurate and detailed diagnoses of conditions, greatly speeding up the process of treatment. And in retail, RAG can enable an even deeper contextual understanding of customer behavior and preferences, and support targeted content and offers for shopping experiences that are even more personalized.
RAG can also address many of the safety and ethical concerns that still persist around AI in general. It’s vital that any AI deployment is reliable, free of bias, and is not responsible for creating misinformation, and RAG can enable that by reducing hallucinations and putting the content generated in the correct contexts. And it’s for that reason, among so many others, that RAG will be talked about more and more in the months and years ahead - so there’s no time to lose in getting on board.
To discuss RAG in more detail, and find out how you can leverage this and other Generative AI technologies to your advantage, get in touch with the Ciklum team today.

By Lucian Gruia

Head of Data Science
12+
Lucian, a seasoned AI Lead with 12+ years in Telecom, Fintech, and Aerospace, specializes in real-time systems and AI-driven solutions. He blends technical prowess with strategic design, delivering impactful, data-centric innovations.
Blogs
Discover Similar Insights

How Enterprises Use Generative AI to Automate Knowledge-Heavy Workflows
Learn More
Enterprise AI Automation: A Practical Guide to GenAI, AI Agents and Intelligent Workflows
Learn More
Payments Without Friction: Modern Checkout Is Your Competitive Edge
Learn More
The 2026 GenAI Watchlist: Five Trends That Will Redefine Technology
Learn More